Case study Codos: 96% trafności, mniej danych, szybsze działanie
Klient_
Codos Foundation to szwajcarska organizacja non-profit. Firma stworzyła apliakcję która motywuje do ekologicznych wyborów transportowych.
Dzięki AI i machine learning platforma mierzy redukcję emisji CO2, wspierając użytkowników w zrównoważonym stylu życia.
Cel projektu_
Celem projektu było opracowanie algorytmu, który w każdej minucie podróży rozpoznaje sposób lub środek transportu użytkownika, umożliwiając precyzyjne obliczanie generowanej emisji CO2.
System obejmuje wykrywanie takich środków transportu jak samochód, autobus, tramwaj, pociąg, rower, hulajnoga elektryczna, metro, ruch pieszy oraz momenty postoju.
Kluczowym założeniem było także zapewnienie możliwości łatwego rozbudowania algorytmu o kolejne rodzaje transportu bez konieczności znaczących zmian w kodzie.
Dostarczone rozwiązanie_
Rozwiązanie zaprojektowane przez zespół Euvic bazowało na infrastrukturze chmurowej AWS, zapewniając wysoką skalowalność i wydajność. Do realizacji celu projektu zastosowano zaawansowane technologie uczenia maszynowego i sztucznej inteligencji.
Centralnym elementem były sieci neuronowe, w tym:
- Konwolucyjne sieci neuronowe (CNN), które umożliwiały ekstrakcję cech z danych wejściowych w postaci spektrogramów i ciągów liczbowych.
- Transformery (Transformers), które analizowały przetworzone dane oraz kontekst, aby skutecznie wnioskować o rodzaju transportu.
Dodatkowo wykorzystano:
- Ukryte modele Markowa (HMM) oraz metody statystyczne w celu poprawy precyzji klasyfikacji i analizy wyników.
Połączenie tych technologii pozwoliło na stworzenie algorytmu zdolnego do dokładnego rozpoznawania i klasyfikacji środków transportu w czasie rzeczywistym, co było kluczowym elementem sukcesu projektu.
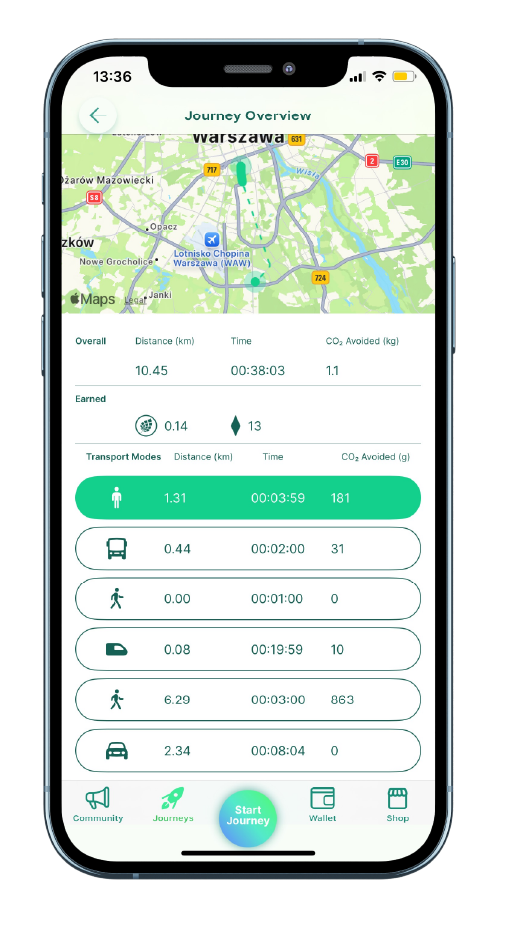
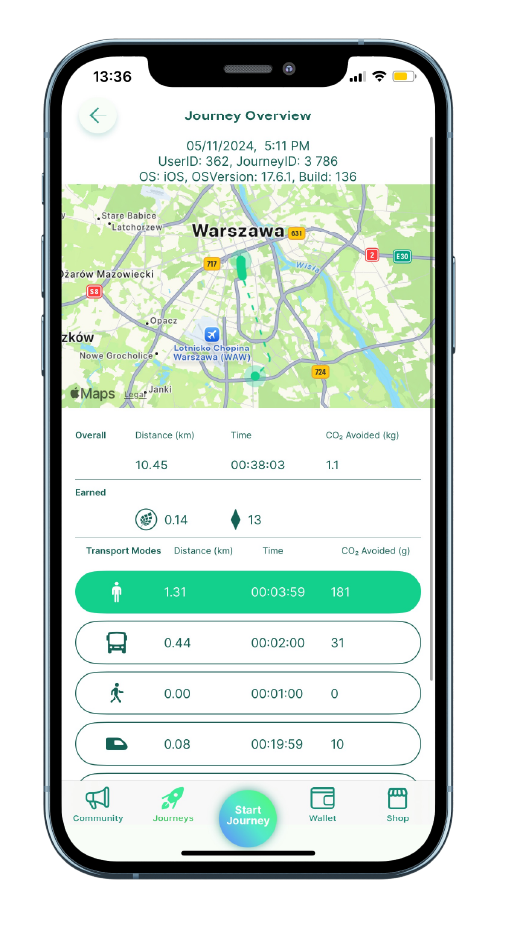
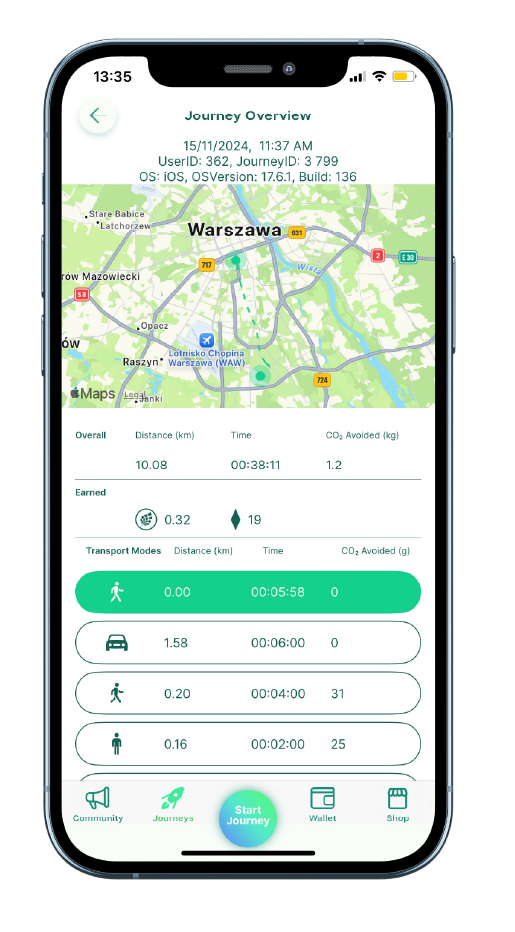
Architektura rozwiązania i kluczowe komponenty_
System oparto na elastycznej architekturze mikroserwisowej, która wspierała skalowalność i łatwą integrację z istniejącymi systemami klienta.
W skład rozwiązania wchodziły następujące kluczowe komponenty:
- Moduły przetwarzania danych czasowo-seryjnych: odpowiedzialne za przetwarzanie danych zbieranych przez urządzenia mobilne użytkowników.
- Moduły klasyfikacji transportu: realizujące identyfikację środka transportu w oparciu o modele uczenia maszynowego.
- Serwisy monitorujące i analizujące wyniki: umożliwiające dostęp do danych, raportów oraz wizualizacji wyników.
Rozwiązanie działało w chmurze AWS, wykorzystując usługi takie jak:
- Amazon S3 do przechowywania dużych zbiorów danych,
- Amazon EC2 do zaawansowanych obliczeń w trakcie trenowania modeli,
- Amazon Lambda do wdrażania modeli oraz zarządzania ich działaniem w czasie rzeczywistym.
Kluczowe technologie, takie jak CNN i Transformers, były centralnym elementem algorytmu, gwarantując precyzję klasyfikacji i możliwość łatwego rozszerzania systemu o nowe środki transportu w przyszłości.
Metodologia_
W projekcie wykorzystano szereg frameworków i narzędzi, które umożliwiły skuteczne osiągnięcie celów. PyTorch został wykorzystany do budowy modeli uczenia maszynowego, umożliwiając elastyczne projektowanie i szkolenie sieci neuronowych, w tym konwolucyjnych sieci neuronowych (CNN) i transformatorów.
Pandas, NumPy i Scikit-Learn zostały wykorzystane do zarządzania i przetwarzania danych szeregów czasowych, a Matplotlib i Plotly do wizualizacji wyników.
Cały proces był zarządzany i monitorowany za pomocą AWS, a Jira ułatwiała ogólny proces opracowywania algorytmów.
Technologia i metodyki użyte w projekcie_
W projekcie zastosowano szereg frameworków i narzędzi, które umożliwiły efektywną realizację celów.
Do budowy modeli uczenia maszynowego wykorzystano PyTorch, co pozwoliło na elastyczne projektowanie oraz trenowanie sieci neuronowych, w tym konwolucyjnych sieci neuronowych (CNN) i Transformerów (Transformers).
Do zarządzania danymi czasowymi oraz ich przetwarzania użyto Pandas, NumPy i Scikit-Learn, natomiast wizualizacje wyników były tworzone za pomocą Matplotlib oraz Plotly. Całość była zarządzana i monitorowana przy użyciu AWS, a w zarządzaniu całym procesem budowy algorytmu pomagała Jira.
Zalety rozwiązania_
Rozwiązanie znacząco zwiększyło efektywność rozpoznawania środków transportu u klienta z początkowej trafności na zbiorze testowym wynoszącej około 80% do wartości 96%, gdzie warto zaznaczyć, że błędy na tym poziomie są także powodowane przez niedokładność zbioru testowego (4% błędów nachodzi na margines błędu ludzkiego).
Dodatkowo dostarczony model przetwarzał mniejszą ilość danych dzięki kompresji, co pozwoliło na znaczne obniżenie kosztów związanych z mocą obliczeniową, przechowywaniem oraz szybkością działanie samej sieci neuronowej.
Nowy model doprowadził do znacznie lepszego doświadczenia użytkownika z aplikacją poprzez mocno usprawnioną klasyfikacje danych z dużo większą trafnością. To przekładało się na pozytywny odbiór, jako że aplikacja mogła poprawnie wyliczyć CO2 wyemitowane przez użytkownika podczas podróży i odpowiednio go nagrodzić.
Wyzwania_
Podczas pracy nad algorytmem napotkano wiele wyzwań. Dużym problemem było odróżnienie autobusów od samochodów, przy czym skutecznym rozwiązaniem okazała się zmiana architektury sieci neuronowej, dodatkowa obróbka statystyczna danych oraz skupienie modelu na informacji wyciąganych z akcelerometru. Od początku wyzwanie także stanowiła wielkość i szybkość modelu. Zarówno model i przetworzenie dla niego danych miało zajmować mało czasu. W tym celu kod był optymalizowany przy użyciu biblioteki PyTorch, a obróbka danych przy użyciu Polars oraz Numpy. Ostatecznie warto wspomnieć o problemach z jakością danych treningowych, które nie zawsze odzwierciedlały rzeczywistość.
Rozwiązaniem była wpierw implementacja filtrowania na podstawie czynników logiczno-statystycznych, jednak z czasem w miarę ulepszania się modelu i zarazem większej potrzeby poprawnych danych, w skrajnych przypadkach pomagały własne narzędzia do manualnej analizy.
Po drodze zdarzały się także mniejsze wyzwania jak np. optymalizacja wybranych procesów w całej infrastrukturze, próby wykorzystania źle oznaczonych danych w treningu, problemy ze stabilnością nauczania modelu, analiza niepoprawnych wyników itd. Jednak większość z nich nie stanowiła problemu i chwila uwagi oraz pracy wystarczyła,
aby je pokonać.
W konsekwencji udało się przede wszystkim obniżyć (miejscami znacząco) koszty związane z działaniem całego systemu. Ponadto sama szybkość oraz jakość wyników zdecydowanie wzrosła.
Wnioski_
Projekt dostarczył cennego doświadczenia w pracy z zaawansowanymi modelami sieci neuronowych, wykorzystującymi technologie CNN i Transformers. W trakcie realizacji wielokrotnie potwierdziło się, że jakość i obróbka danych odgrywają kluczową rolę – często nawet większą niż ich ilość. Szczegółowa analiza danych przed rozpoczęciem i w trakcie prac okazała się niezbędna, a sposób ich zbierania oraz ocena jakości wymagały precyzyjnego uzgodnienia z dostawcą. Drobne szczegóły, takie jak krótki brak sygnału GPS czy błędne klasyfikowanie korka jako postoju, mogły znacząco zaburzyć działanie modelu. Finalnie okazało się, że sieć osiąga znacznie lepsze wyniki, ucząc się na mniejszej ilości wysokiej jakości danych z precyzyjnie dobranymi cechami, niż na pełnym, nieprzefiltrowanym zbiorze.
Dodatkowo, metoda małych kroczków w eksperymentach okazała się bardzo skuteczna. Pozwalała na dokładne monitorowanie postępów i umożliwiała świadome decyzje o wycofaniu się z nieefektywnych działań lub pełnym wdrożeniu sprawdzonych rozwiązań. Wspieranie eksperymentów wskaźnikami statystycznymi, takimi jak macierz pomyłek, tabela F1, czy opracowanie własnych metryk i wykresów pod konkretny problem (np. wskaźnik spójności predykcji lub wizualizacja wyników na mapie), znacząco poprawiło proces analizy i wyników.
Na uwagę zasługuje również niezwykła wartość publikacji naukowych oraz dokumentów technicznych dostępnych w zasobach internetowych, które często oferują gotowe rozwiązania dla problemów zbliżonych do tych napotkanych w projekcie. Ich połączenie z rozwiązaniami wypracowanymi wewnątrz zespołu dało znakomite rezultaty.
Podsumowanie_
Projekt skoncentrował się na znacznym zwiększeniu precyzji klasyfikacji środków transportu w aplikacji klienta, osiągając wzrost trafności z początkowych 80% do 96%. Dzięki zastosowaniu kompresji danych model przetwarzał mniejsze ilości informacji, co obniżyło koszty obliczeniowe i poprawiło szybkość działania.
Z biznesowej perspektywy, usprawniona klasyfikacja pozytywnie wpłynęła na doświadczenie użytkowników, zwiększając wiarygodność obliczeń śladu węglowego i prawdopodobnie motywując ich do ekologicznych zachowań.





