Immunovia – Revolution in pancreatic cancer detection
Implementing IMMray® analysis, a flexible technology platform for developing bioinformatics-assisted blood-based tests and developing a front-end application.

Immunovia AB is a pioneering diagnostics firm dedicated to transforming the field of blood-based diagnostics and enhancing the chances of survival for individuals battling cancer.
Client:
Immunovia
Industry:
Healthcare
Country:
UK
Service:
Development of front-end application, IMMray® analysis
Team:
Frontend Developer, DevOps, Python Developers
Challenge
Immunovia wanted to create applications that would enable the processing, storage, and management of laboratory assay data, thereby streamlining the work of laboratory technicians in developing the products. They required these applications to aid in producing the products and using them to test clinical samples and provide early indications for the presence of diseases, such as pancreatic cancer.
According to that, Immunovia requested Euvic to develop front-end applications for:
- Lab Test (LDT) for Pancreatic Cancer Detection: ‘IMMray® Pd’ test
- In-House Reagent Production Software: ‘PdIESProd’
- R&D Software Suite: ‘IESDev’ for Process Enhancement and New Test Algorithms

Solution
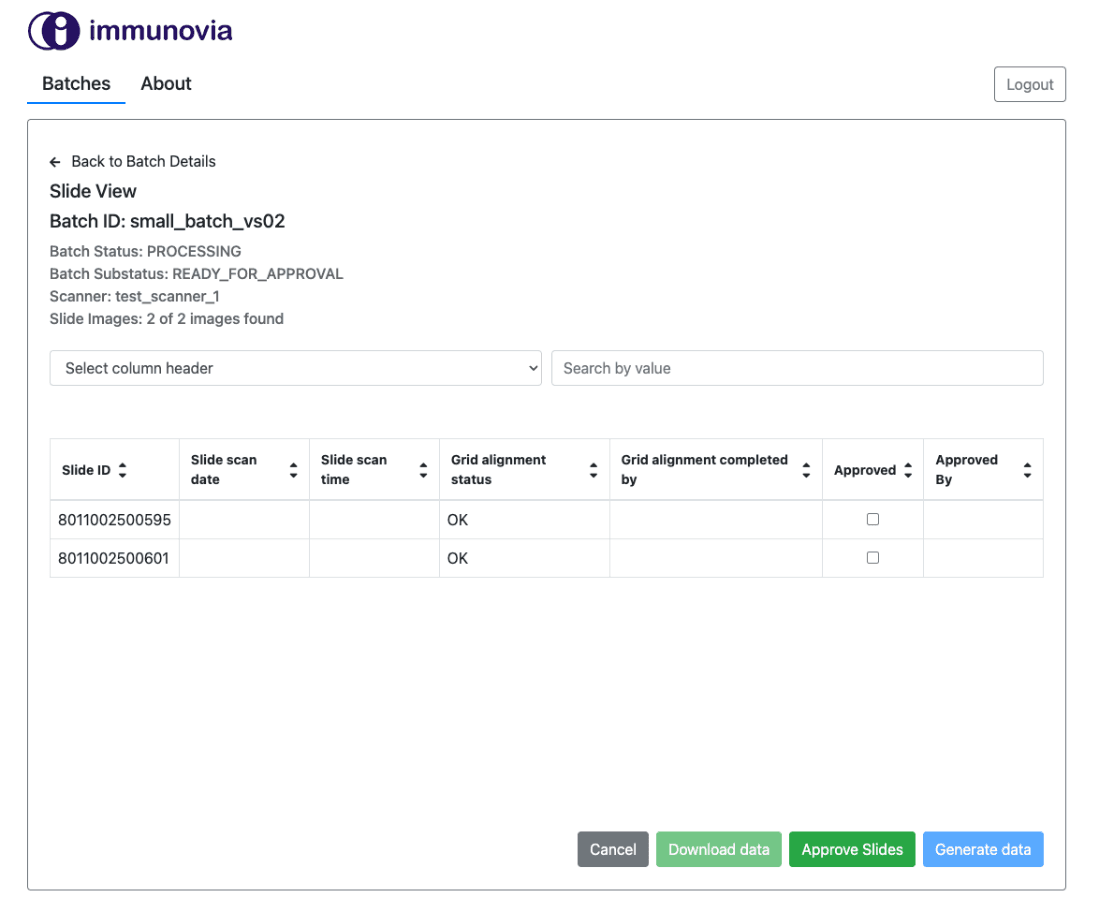
Although the client already had partially completed software to extract raw data from scanned microarray slide images, its development team was relatively small. To meet the project’s demanding criteria, it was imperative to bring in an accomplished front-end developer. This addition was pivotal in augmenting the development team, ensuring the maintenance of a substantial codebase, and addressing all the necessary business and medical prerequisites. Consequently, the Euvic team played a vital role in bolstering the existing team, enabling them to fulfill the project’s requisites.
As a result, we have helped the client with the development of a front-end application supporting pancreatic cancer detection by processing, storing, and managing medical data. Moreover, we supported the development of scalable, cloud-configurable software.
Impact
We have developed software designed to create reagents, produce reagents, and assist in detecting pancreatic cancer when these reagents are utilized with patient samples.
This software was developed following the guidelines from the IEC 62304 standard for medical device software, serving as a general principle for maintaining quality that surpasses the minimum requirements for LDT tests and production instruments.

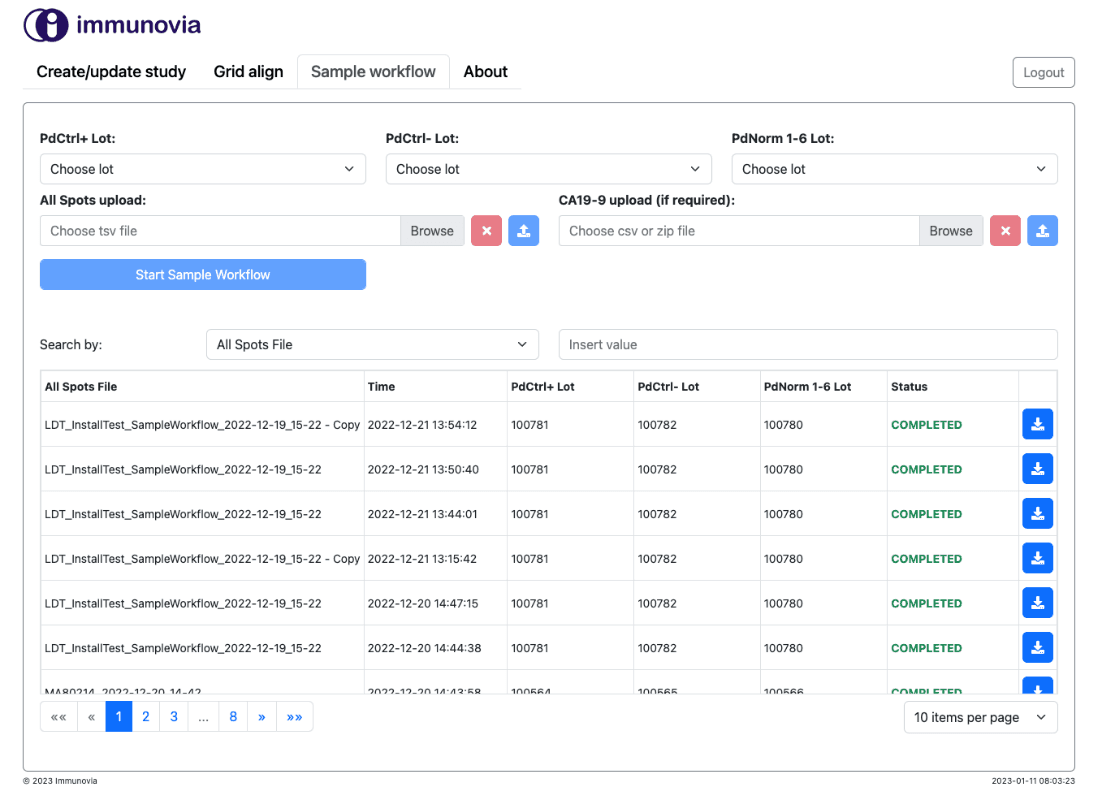
Tools and Technologies
Python
AWS
Angular
NodeJS
IESDev
IES-LDT
IESProd
Summary
- Optimizing the processing of sample images from the scanner to obtain test results.
- Automatically calculating acquired data.
- Meeting all business and medical requirements.
- Facilitating the work of laboratory technicians.











